GraphQL vs REST
GraphQL is an alternative approach to provide an API, so it's natural to compare it with REST. In this chapter we'll look into the same data model and how we can represent that in the two ways. Then we'll discuss the benefits of using GraphQL.
What is REST
REST is based on HTTP paths and verbs to provide operations for resources. For example, let's consider a simple data model where we have users and users can have todo items. A simple API could offer retrieving, creating, and listing objects:
- GET
/user=> List users - GET
/user/:id=> Get user by ID - POST
/user=> Create user - GET
/user/:id/todo=> List todos for user - POST
/user/:id/todo=> Create todo for user
To get the list of users, the GET /user can return this response:
{
"users": [
{
"id": "user1",
"name": "Bob"
},
{
"id": "user2",
"name": "Joe"
}
]
}Then to get the todos for the first user, a GET /user/user1/todo can return this:
{
"todos": [
{
"name": "todo1",
"checked": false
},
{
"name": "todo2",
"checked": true
}
]
}In this comparison we'll focus on queries, as this is where GraphQL provides more benefits. Modifications are way simpler and GraphQL adds almost nothing there as you'll see in the Mutations chapter.
Following the REST approach gives a good idea what is possible with the API just by looking at the verb + path pairs. It's easy to see what objects are available just by seeing their names in the paths, and the hierarchy among them. In the above example, todo items are part of users, which is evident from the /user/:id/todo path.
On the other hand, nothing enforces a REST-like API to follow these conventions, it's entirely up to the developer (or the designer of the API) to make it easy for others to understand the structure. Also, there is no built-in way to document a REST API. To do that, you'll need to rely on other projects, for example, OpenAPI.
Queries in REST are HTTP requests to the API endpoint. Usually, a query returns one object (/user/:id) or a list (/user) and any referenced objects need a separate request (/user/:id, then /user/:id/todo).
What is GraphQL
GraphQL is based on graphs. There are nodes, that are similar to objects in REST, and edges between them. In our previous example we had users and todos, and a connection between a user and a todo is that a todo belongs to a user.
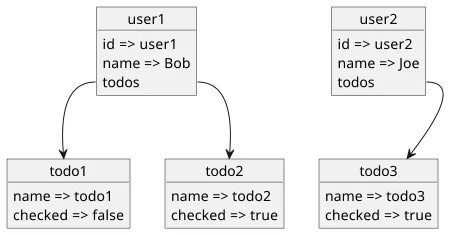
In the above data model, the user objects have a todos field and the todo items are referenced through that field. You can think of it as a label on the edge that distinguishes how the objects are connected. For example, let's say users can have friends and blocked users. In that case, two users can be connected in two ways: friend or blocked.
This is visualized like this:
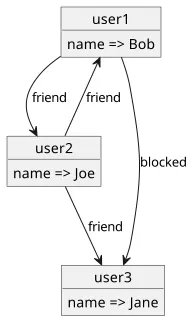
Also, edges are directed. A user might block another user but that might not be mutual.
GraphQL comes from Facebook, and you can see how it naturally translates to a social network. People have friends (a connection between the two user objects), they can publish posts (a connection between a user and a post), can comment (a connection between a post and a comment, and also between a user and the comment), and so on. Graph-based APIs work best where queries need related data to an object. For example, getting the todo items is easy to define as a graph operation (just follow the edges from the user). But ultimately, everything can be implemented in GraphQL.
Queries in GraphQL define the whole structure the requester needs. For example, a single query might get a user object and all todos for that user. Or, in a more complex example, a query might get a user, its latest posts, its friends, and their latest posts too.

GraphQL needs a schema that defines the object graph and what connections are available from each type. We'll discuss this in detail in the Schema chapter.
Getting back to our original data model of users and todos, a query can ask for a specific user and its todo items:
query {
user(id: "user1") {
name
todos {
name
checked
}
}
}A response contains all the fields:
{
"data": {
"user": {
"name": "Bob",
"todos": [
{
"name": "todo1",
"checked": false
},
{
"name": "todo2",
"checked": true
}
]
}
}
}The path to GraphQL
An excellent article from PayPal titled GraphQL: A Success Story for PayPal Checkout illustrates the steps teams usually take to move from REST-like APIs to GraphQL and what the motivations are.
In this chapter we'll take a look into how they progressed from a REST-like API to GraphQL.
Step 1: REST-like
A new API is usually created with purity in mind, and REST is a great choice for that. There is an endpoint for each object, allowing CRUD (Create, Retrieve, Update, Delete) operations for them. For a backend developer, this is the easiest, as these objects usually directly map to the database. Then the frontend(s) can get what it needs by fetching the objects.
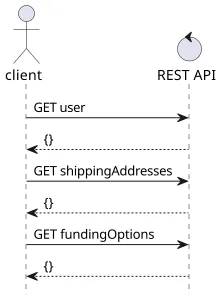
This is great from an architectural perspective, but terrible for user-experience. The number of requests and roundtrips the client needs to do to show the page to the user is the #1 contributor to slowness. And REST-like APIs, especially those that follow data normalization best practices, require several requests in series to fetch all data.
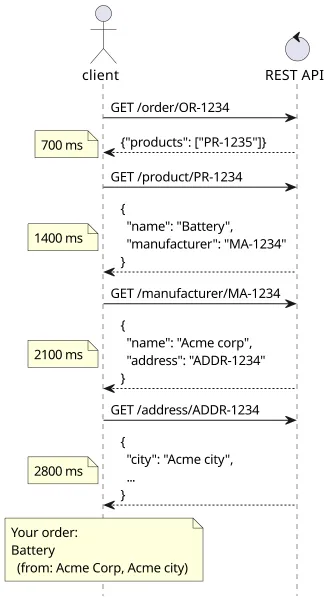
In the above example, showing a simple overview of the order required 4 roundtrips: order -> product -> manufacturer -> address. This structure follows all the best practices for database architecture and the API is a pure representation of what is stored, but the UX is awful.
Step 2: Orchestration endpoint
The logical next step is to create an endpoint to aggregate the data, so the client needs to send only one request, then the backend fetches the data from the REST API locally. Since the roundtrips are shorter (the REST API is local to this endpoint) this way, the lag the client experiences is just one request.
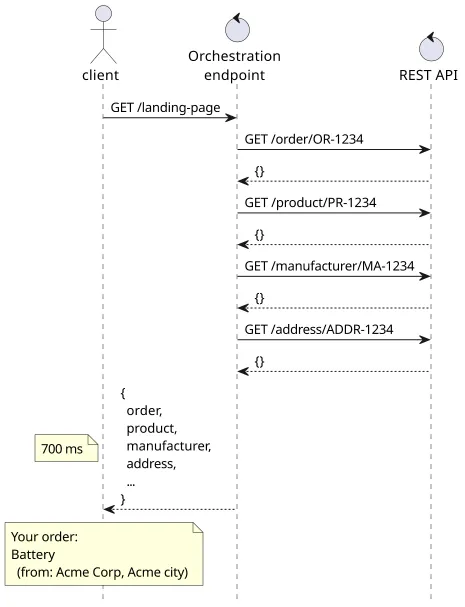
This solves the roundtrips problem, but introduces a different one: overfetching. What if a client does not need to show the address of the manufacturer? For example, a mobile app might hide the details by default due to the smaller screen. If the endpoint returns everything any of the clients needs then most of the data will be discarded.
A bad solution is to provide a separate orchestration endpoint for every client. Instead of a single /landing-page, there could be a /landing-page-mobile and a /landing-page-desktop, each client calling the appropriate one. In practice, this leads to every person working on a client having a separate endpoint.
Step 3: Dynamic orchestration
The problem with an orchestration endpoint we used in the previous step is that it's static by nature. One can return all the data for a landing page or a checkout form, but not both. Instead of the client defining what it needs, the server provides data only for some cases.
The logical next step is to make a dynamic orchestration endpoint where the clients can define what they need and the same request can respond to all use-cases. This sounds great at first: the REST-like API keeps its one object-one endpoint structure, then there is one general-purpose orchestration layer on top of that, and clients can enjoy the 1-roundtrip performance with just the data they need.
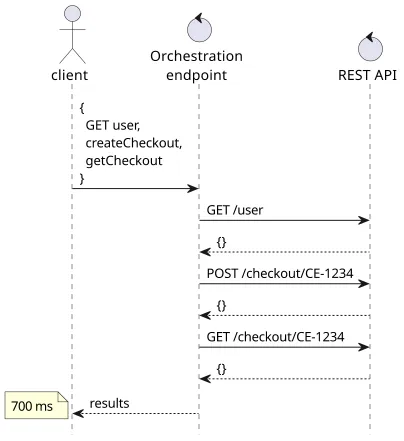
This is a great solution on the whiteboard but there are problems with it in practice. Since it's based on a REST-like API that builds on HTTP, the orchestration API also needs to support all these features. An operation is made of a verb (GET, POST, PUT, ...), a path (/api/user), an optional request body, headers, query parameters, cookies, status codes, content types, and so on. To make a truly universal endpoint, it needs to support a lot of features and they make it complicated for the frontend developers to write these aggregated requests.
Then there might be dependencies between the individual requests. Fetching multiple things can go in parallel, but when you want to store something and then retrieve some data, the endpoint needs to know what depends on what. Worse still, a query can depend on the result of another query, such as you might want to fetch the manufacturer for the product, but the product query returns the identifier.
Step 4: GraphQL
GraphQL solves these problems. It acts as a universal orchestration endpoint where each field acts like a separate operation. The backend developer needs to define how the server provides a value for a field (this piece of code is called a resolver), then client can define what they want and the response contains only that data.
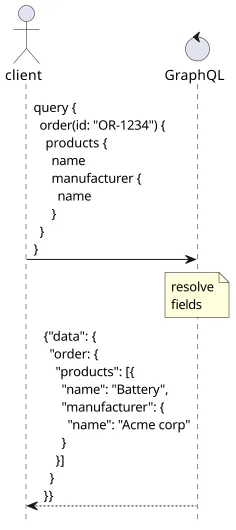
It handles dependencies by separating read-only operations (queries) from write-read ones (mutations) and handles dependent data by relying on a hierarchy between the types. And it supports only a subset of HTTP, so UI developers can focus on types, fields, and arguments. Then the schema provides a centralized documentation.
Moreover, GraphQL is a standard unlike the home-grown REST API aggregator some companies came up. If somebody is familiar with the basics they can start working on any parts of the stack immediately.
Advantages over REST
Batteries included
GraphQL relies on a schema to define the types and their fields (data and connections) which means all GraphQL-based APIs share a single documentation format that external tools can rely on. This means visualization, security analysis, and documentation generation are all possible with support to all GraphQL APIs out there. For example, GraphQL inspector detects changes between schema versions.
The query format is also standardized, so you can use advanced features, such as variables, directives, and fragments, with app GraphQL-based backends. This adds powerful features right from the start. Moreover, introspection queries allow extracting structure from a live endpoint, which is used by several visualizers. And the common query format allows tools to analyze what is sent and even provide cost estimates.
This is all possible with REST too, but that relies on opt-in. For example, a REST API can use OpenAPI that provides documentation and introspection capablities, but many APIs don't use that. With GraphQL, you can be sure that what is required by the standard is available.
This is a double-edge sword though. It's great to have features that you can be sure are present, but that also complicates the API when a lot of those extra things are not needed. Also, when the specifications evolve and add more features they need to preserve backwards-compatibility. This means legacy stuff accumulates over time.
Moreover, unused features make harder to secure an endpoint. For example, it's challenging to get a list of all fields requested in a query due to aliases, inline fragments, and directives. If a security solution depends on this list, it needs to include all features of GraphQL.
No overfetching or underfetching
REST-based APIs usually suffer from the n+1 request problem. Let's say a client needs to show all the users and their todo items. For this, it needs to send multiple requests:
- GET
/user - GET
/user/user1/todo - GET
/user/user2/todo
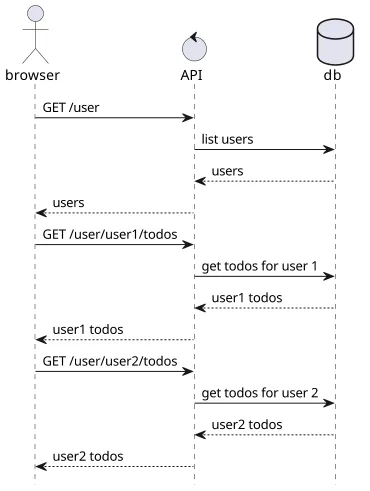
While the second part can be parallelized (the /user/:id/todo calls rely only on the result of the /user call), getting all the data still requires an extra roundtrip. And in practice, the number of serial requests is the main reason a webapp is slow. This is called underfetching, as the response contains less than the client needs, and it needs other requests to receive the missing parts.
With GraphQL, a query can describe all the data it needs in advance and it's up to the server to collect it and return in a single response. For example, this query asks for all users, their data, and all their todo items:
query {
allUsers {
name
todos {
name
checked
}
}
}The response contains all the data that the client needs, so there is no need to send a second request. In the ideal case, a client needs to send only one request and the response contains everything it needs and nothing more. Defining the fields fetched prevents overfetching, when the response contains more than the client needs. With a REST-like endpoint, responses usually contain the full object. In GraphQL, the client defines what it needs.
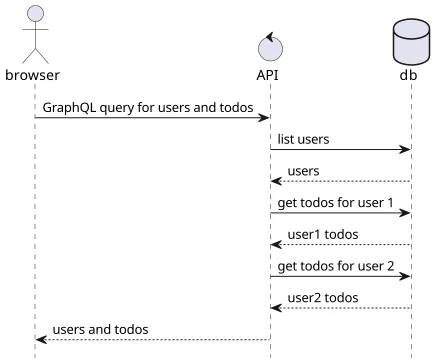
Notice that GraphQL does not reduce the amount of work needed to fetch the information, it just shifts that from the client to the server. If the users and the todo items are stored in a database, the backend still needs to send the same amount of requests to it. But this is hidden from the client and the backend <-> database communication is usually way faster than the client <-> backend.
Disadvantages
While GraphQL solves problems with multiple roundtrips, it also brings its own problems. In this chapter we'll look into some of them and see what we can do about them.
Expensive queries
While it's great that clients can define what data they need, this also means a query can fetch a lot of data straining resources on the backend. For example, a query that gets a single object and some properties of it is cheap:
query {
user(id: "user1") {
name
}
}This query needs a single query to a database and produces a small response.
But a similar query that fetches a user's second order friends graph:
query {
user(id: "user1") {
name
email
friends {
name
email
friends {
name
email
}
}
}
}The query itelf is not that more complex but it might generate a huge load on the backend. If the user has 200 friends and they each has 200 friends, it will contain a total of 4201 user objects. Worse still, if the email addresses are stored in a separate system, such as a user directory, that needs an additional HTTP request per user. Worse case, the above query can:
- fetch 4201 objects from the database
- send 4201 requests to the user directory
- generate a response of hundreds of kilobytes
Because of this, standard rate limiting solutions (request/sec per user per endpoint) do not work. What you can do is add static analysis that tries to quess what the cost of the query is likely to be and deny too expensive ones. But this is something you need to opt-in and there are no standard solutions yet.
Non-atomic queries
There is an excpectation from clients that a query returns a point-in-time view of the data and the response is always consistent. This is easier with a REST-like API as it provides access to one object at a time, and also there is usually one handler for one object. This makes it possible to rely on the database's transactions. Because of this, it usually can not happen that the client gets back a "half object", as some other process deleted it while the handler read the properties.
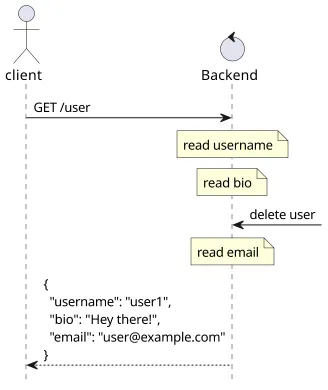
But GraphQL works differently. There is no single handler that responds to the query, but there are fields that the backend processes and provides a value for. And since these are separate processes, if the database changes during a query it can return inconsistent objects or even throw an error.
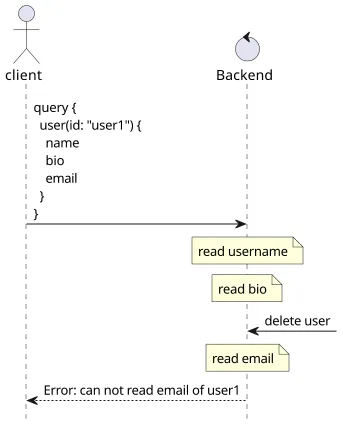
Because of this, clients should always expect that a query might succeed if retried for non-client-side errors.
Different terminology
And, of course, a different technology comes with different parts and different terminology. It's less of a problem for clients, as they get most of the benefits of the schema, but developing a GraphQL backend is different from a REST-like one.
Especially the resolver architecture and access control needs a lot of getting used to that makes it harder to adopt the technology.